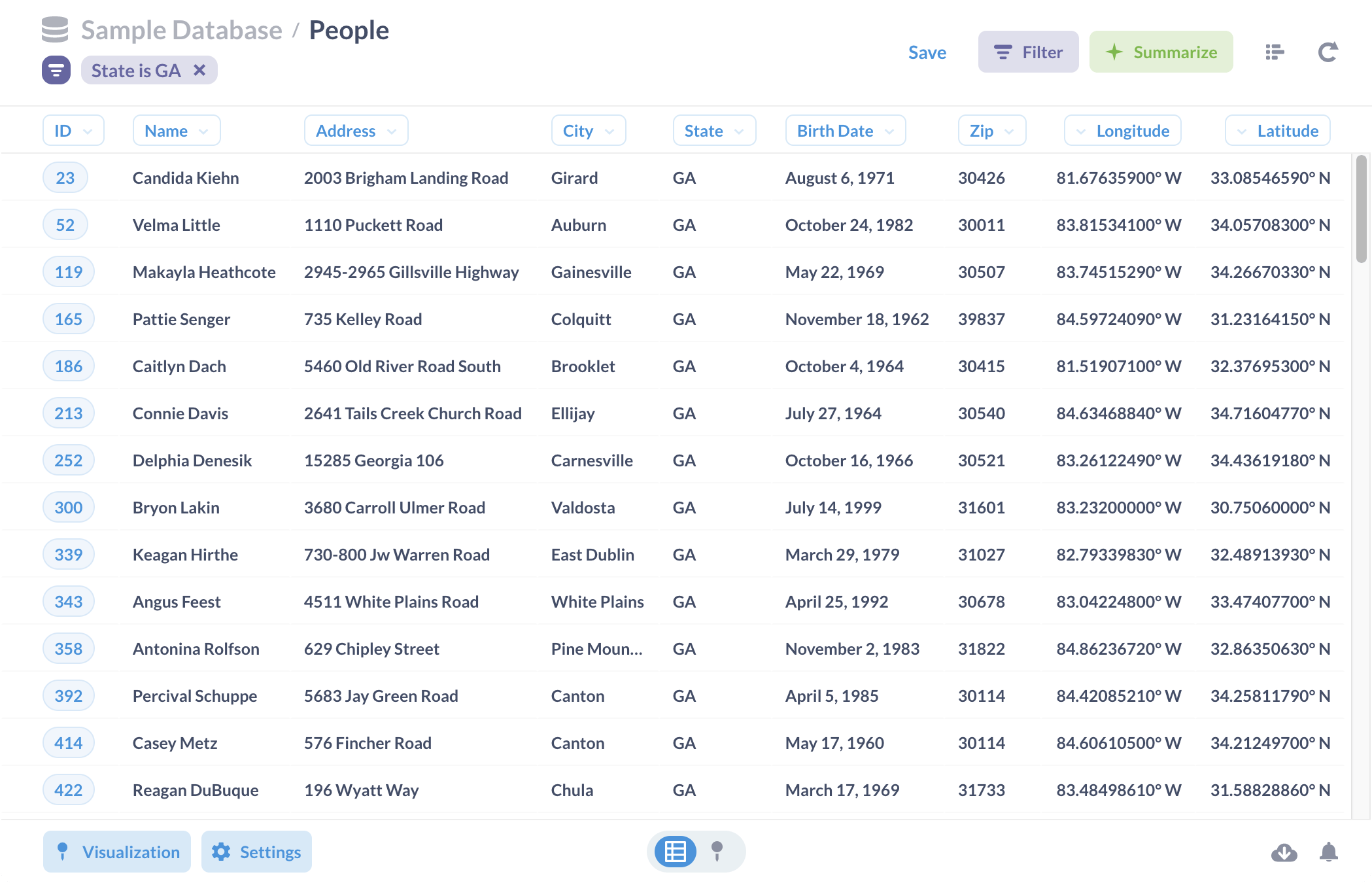
Hey guys, I'm building erlog to try and solve problems with logging. While trying to add logs to my application, I couldn't find any lightweight log platform which was easy to set up without adding tons of dependencies to my code, or configuring 10,000 files.
ErLog is just a simple go web server which batch inserts json logs into an sqlite3 server. Through tuning sqlite3 and batching inserts, I find I can get around 8k log insertions/sec which is fast enough for small projects.
This is just an MVP, and I plan to add more features once I talk to users. If anyone has any problems with logging, feel free to leave a comment and I'd love to help you out.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I settled on a happy/ok midpoint recently whereby I dump logs in a redis queue using filebeat as it’s very simple. Then have a really simple queue consumer that dumps the logs into clickhouse using a schema Uber detailed (split keys and values), so queries can be pretty quick even over arbitrary fields. 30,00 logs an hour and I can normally search for anything in under a second.