SHA-3 does seem to have relatively little to offer by way of incentives to switch. "Just as good" isn't motivation, and any notions of higher cryptographic strength haven't been extensively discussed. "Easier to implement in hardware" will be more compelling when such hardware exists.
From that, SHA-3 certainly doesn't run significantly faster than alternatives (variants of BLAKE do indeed outperform it), but it seems roughly on par with SHA-256/SHA-512. But "on par" doesn't give any incentive to switch.
I wonder how much relative attention the SHA-3 winner (Keccak) gets compared to other alternatives, like BLAKE?
> "Easier to implement in hardware" will be more compelling when such hardware exists.
Most things are software;
from previous experience we know that it basically takes 10 to 15 years between introduction of a primitive (AES and SHA-2 both standardised around 2000; ISA extensions for mainstream CPUs introduced in 2010-2017). From the software PoV SHA-3 would be a rather large regression in performance with a "maybe it's fast by 2030 if Intel is really nice" attached. BLAKE2 on the other hand is an improvement in performance and offers a function that is more modern overall. (E.g. not length-extensible thus low-overhead keyed hash usage, flexible output sizes, tree hashing built-in)
Yes, perhaps before they choose the next "faster in hardware" crypto algorithm, they also get a commitment from the major chip makers (Intel, AMD, Qualcomm, MediaTek, etc) that they will implement them within let's say 2 years after the contest is over.
Otherwise it's just hope that the chip makers will implement it when the algorithms are chosen, and I'm not sure that's good enough after a carefully orchestrated 5-year process of choosing a next-generation algorithm.
If they can't get that commitment, then they should choose whatever is faster in software (granted all the other factors are more or less equal).
>I'm curious about the statement that SHA-3 is slow; [...] I wonder how much relative attention the SHA-3 winner (Keccak) gets compared to other alternatives, like BLAKE?
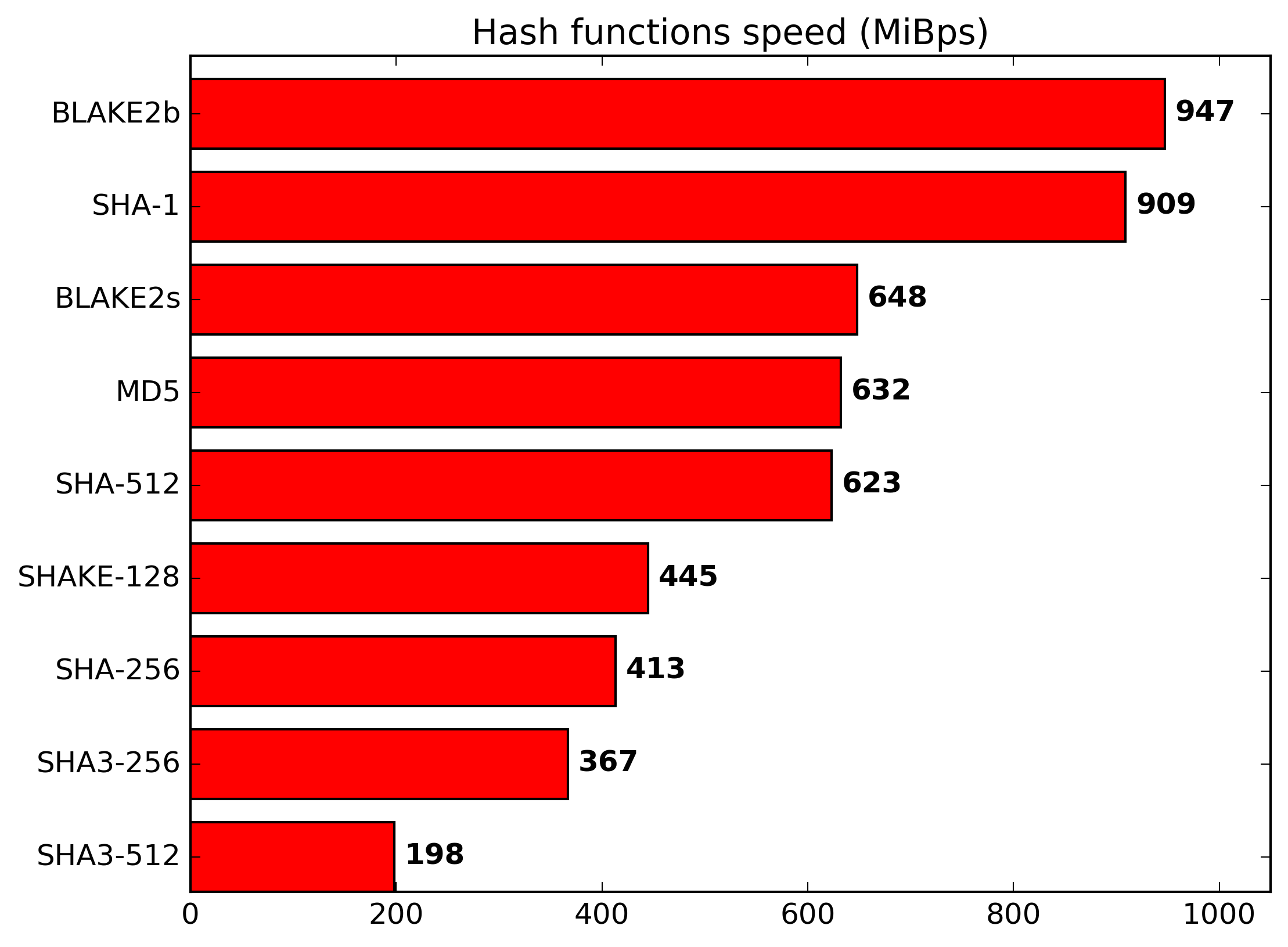
Coincidentally, I ran a bunch of hash performance benchmarks last week. These were my findings:
test: hash a 500MB block of memory.
hardware: Intel Core i7-5820K Haswell-E 6-Core 3.3GHz
compiler: MSVC2017 (19.10.25019), 32-bit exe:
blake2sp - official reference code[1] 153MB/sec
SHA3 - Keccak official reference code[2] 12MB/sec
SHA3 - rhash sha3[3] 45MB/sec
SHA3 - Crypto++ library v5.6.5[4] 57MB/sec
SHA256 - Crypto++ 181MB/sec
SHA256 - MS Crypto API[5] 113MB/sec
SHA1 - MS Crypto API 338MB/sec
MD5 - Crypto++ 345MB/sec
CRC32 - Crypto++ 323MB/sec
The conclusion is that the fastest SHA3 implementation (Crypto++ lib with its assembly language optimizations) is more than 2x-3x slower than SHA256. I can't speak for SHA3 implemented in FPGA/ASIC but as far as C++ compilation targeting x86, it's slow. I've been meaning to try the Intel Compiler to see if it yields different results but haven't gotten around to it yet.
Blake2sp is fast. The official reference code is not quite as fast as Crypto++ implementation of SHA256 but it's faster than Microsoft's Crypto API of SHA256. (There are several variants of BLAKE and I chose blake2sp because that's the algorithm WinRAR uses. I think the specific variant of BLAKE that directly competed with Keccack for NIST standardization is slower.)
I'll just say this - there are private implementations of Keccak that blow the pants off of those numbers.
Keccak is one of the primary functions in Ethash (Ethereum mining). It is heavily researched and completely destroys SHA2 performance-wise if you have the right implementation.
Also, Keccak doesn't require the construction of a key-schedule, and can be implemented much more elegantly in parallel (SIMD software) and in hardware than SHA2.
I guess 32-bit x86 performance is maybe not the best benchmark. I think people aren't optimizing for that ISA to the same extent as they are optimizing for x86-64, 64-bit ARMv8, or 32-bit ARM.
If you care about performance and you don't have dedicated SHA-256 instructions then on a 64-bit platform you should evaluate SHA-512 as it is much faster. If you only have 256 bits of storage available then truncate its output to 256 bits. IIRC, it's about 1GB/sec on my Haswell laptop.
>I guess 32-bit x86 performance is maybe not the best benchmark.
I compiled for 32bit instead of 64bit because I wanted the same executable to also run on a 32bit Macbook. When Thomas Pornin ran benchmarks[1] in 2010 for both 32bit & 64bit, the SHA256 hash performance didn't change as much as the SHA512. I'll recompile for 64bit and report back if there was a massive difference.
Mismatches can show an interesting property. It is likely that SHA-256 is slower than Keccak on 64-bit platforms, and that SHA-512 is slower than Keccak on 32-bit platform.
Hmm, something is wrong with your benchmark: the absolute values in MB/s are very low for i7, and relative too — blake2sp should be much faster than SHA256.
blake2sp is indeed faster than Microsoft's builtin Crypto API for SHA256. However, it is not as fast as Wei Dai's Crypto++ library implementation of SHA256 that has lots of hand tuned assembly language code.
The official C source code for blake2sp does not have assembly language primitives in it. It's very possible that if an assembly language expert wrote optimizations for blake2sp, it would beat Crypto++ SHA256 performance.
The code I used is really simple. Used files "blake2sp-ref.c" and "blake2s-ref.c" from the BLAKE website. The hash code (no loops) is:
blake2sp_state S[1]; // BLAKE 1 element array of the struct for state
blake2sp_init(S, BLAKE2S_OUTBYTES);
blake2sp_update(S, BufInput, iBuffersize);
blake2sp_final(S, hashval_blake2sp_bytes, BLAKE2S_OUTBYTES);
... where iBuffersize is 500MB but I got the same results at larger buffer sizes 1GB+.
With that code, I'm guessing anyone can whip up a C++ project to benchmark blake2sp in 10 minutes. It would be interseting to see what MB/sec that others achieve.
My pure JavaScript implementation of blake2s (which is approximately half the speed of parallelized sp variant) on 2.6 GHz Core i5 hashes at 170 MiB/s. JavaScript! Whatever you do with your benchmark, you're doing it wrong. Also, there is no reason to use such large buffer sizes, I suspect this only makes benchmarks more unreliable.
>My pure JavaScript implementation of blake2s (which is approximately half the speed of parallelized sp variant) on 2.6 GHz Core i5 hashes at 170 MiB/s.
If I recompile blake2sp with "/O2" optimization, it improves to 171MB/sec. I ran tests with "/Od" optimizations disabled because the default Crypto++ library project has optimizations disabled when it makes the lib file. Therefore, every hash had no optimizations to keep the comparisons apples to apples.
If I recompile blake2sp with "/O2" optimization, it improves to 171MB/sec.
Too slow! You're doing something wrong or measuring some slow implementation :) It should be more than 500 MB/s.
Therefore, every hash had no optimizations to keep the comparisons apples to apples.
That's not apples to apples at all. Most performant code is written specifically to be optimized by compiler. Use /O3 for benchmarking. Also, you just wrote that you were measuring a hand-optimized assembly version and then compared it to a C version compiled with optimization disabled? O_o
I chose 500MB because I wanted the fastest hashes (CRC32, MD5) to take at least 1 second and many data sizes I want to hash will be 10GB+.
Then call the update function with a reasonable 8K buffer many times. Using such large buffers will generate a lot of noise in benchmarks.
* * *
Speaking of JS, you can try my newer implementations/ports by cloning https://github.com/StableLib/stablelib. run ./scripts/build, cd into packages/blake2s (/sha3, /sha256, etc.) and run: node lib/.bench.js Note that SHA-3 (and SHA-512, BLAKE2b [not implemented yet]) is slow in JS compared to SHA-256, BLAKE2s, etc. because it uses 64-bit numbers, so in JS I have to emulate them by using two 32-bit ones for low and high bits.
I do now notice that my ASUS motherboard monitor software is reporting that my CPU is at 1.2GHz instead of 3.3GHz. There's probably something wrong there. However, even if I get it up to 3.3GHz, the relative speeds between different benchmarks won't change. I got the same relative numbers on the Macbook.
>measuring a hand-optimized assembly version and then compared it to a C version compiled with optimization disabled? O_o
Because there's lots of Wei Dai code that's C++ code instead of asm. He delivered his MSVC project with optimizations disabled instead of "/O3" so it made the most sense to start with optimizations disabled everywhere as a preliminary benchmark. If I recompile Wei Dai's code with optimization, it will make Crypto++ perform faster and make blake2sp look slower. In the end, it's a moot point because blake2sp with "/O2" is still slower than Crypto++ SHA256.
>Using such large buffers will generate a lot of noise in benchmarks.
Why? If you study the blake2sp source code, you'll see a loop inside the hash update() function to handle arbitrary sizees of buffers. Why does a loop outside that update() mean "less noise"? Why does adding more function calls of BUFSIZETOTAL divided by 8192 equal less noise?
If I recompile Wei Dai's code with optimization, it will make Crypto++ perform better and make blake2sp look slower.
Just do it. If it's slower, you're doing something wrong. Which implementation of blake2sp are you measuring? It should be at least 1.5x as fast.
Why? If you study the source code, you'll see a loop inside the hash update() function. Why does a loop outside that update() mean "less noise"? Why does adding more function calls of BUFSIZETOTAL divided by BLOCK PROCESSING SIZE equal less noise?
Because you'll be measuring a lot of memory copying time apart from hashing time. Dealing with memory outside of CPU cache introduces a lot of variance.
I suggest that instead of our discussion you should try to reproduce the results of https://bench.cr.yp.to (which is a highly trusted source, e.g. it was used during SHA-3 competition by NIST and participants): if something doesn't approximately match it means you did something wrong. In the process, you'll learn how to properly benchmark hash functions and make some sciency science by reproducing results! :-)
I think I found the issue. In terms of absolute (not relative) MB/sec performance, the main culprit is the slow cpu speed of 1.2GHz single threaded performance instead of 3.3GHz. The other investigations into "/O2 /O3" optimizations or 8k outer loop were red herrings.
However, for relative MB/sec performance comparison to SHA256, it seems to point back to the blake2 official reference code (non SSE) being very slow. Wei Dai Crypto++ also happens to have BLAKE2 algorithm and when I executed that, it ran at 525MB/sec which was faster than SHA256 and also faster than SHA1. No outer 8k chunk loop necessary for Crypto++ benchmark.
>Because you'll be measuring a lot of memory copying time apart from hashing time.
Yes, I notice the numerous memcpy() functions in the blake2s?-ref.c. For additional tests, I rewrote the loop to call update() on chunks and tried various sizes (8k, 16k, 32k, ... 256k, 512k, 1MB). At 256k chunks and below, I got 235MB/sec which was an improvement but still slower than SHA256. As stated above, the real key was to use an optimized BLAKE2 algorithm instead of the official reference code.
I can't tell if the blake2 entries in https://bench.cr.yp.to are using official reference or optimized code so trying to replicate those results with official reference files may be a wild goose chase.
If your machine is throttling the CPU during benchmarks, all bets are off. You need to disable all power management and energy savings or else figure out why your machine is causing a throttle to kick in (likely thermal management). You can't compare any results (even relative to one another) until that issue is resolved.
Yeah, of course reference implementation is a lot slower — it's for algorithm reference, so has readable code, which is slow. It can even be greatly improved by just unrolling loops and inlining message indexing by sigma constants, even without SSE (like my JavaScript implementation).
As for memory copying — I didn't mean memcpy(), what I meant is that your CPU would have to get chunks of your huge buffer from RAM, which is slower and has more unpredictable performance.
>Yeah, of course reference implementation is a lot slower — it's for algorithm reference, so has readable code, which is slow.
Exactly! That's why my original post had the footnote that I using the slower blake2sp reference code. Same situation as the SHA-3 reference code being the slowest implementation.
>As for memory copying — I didn't mean memcpy(), what I meant is that your CPU would have to get chunks of your huge buffer from RAM, which is slower and has more unpredictable performance.
But this observation also applies to all the other hash performance tests. If the blake2sp hash is handicapped by computing large RAM buffers beyond the L1/L2/L3 caches, the MD5/SHA1/SHA256/etc are also handicapped the same way. Whatever "noise" exists in the tests can be evened out by multiple executions.
Restricting the tests to tiny memory sizes that fit in L1/L2/L3 is not realistic for my purposes.
It'd be interesting to see what SHA2-512 would do since I think modern intel CPUs prefer that size to 256. (I could be wrong though as i have no source to cite just something I remember reading.)
You might also want to test out BLAKE2bp, which is optimized for 64-bit platforms, while BLAKE2sp is for 32-bit platforms. So the numbers for BLAKE2 will be even higher
CRC32 is slower because implementing it in software a way that exploits modern CPU's instruction level paralelism is non-trivial, also the obvious way how to implement CRC32 on 32bit byte oriented CPU isn't exactly cache friendly.
I recently came to believe (correct me if I'm wrong) that the recommended XOFs SHAKE128 and SHAKE256 are actually nice and fast, but often when people talk about SHA-3 they focus on the slower "drop-in replacements" like SHA3-256 which are quite conservative.
{kind=link}
I'm curious about the statement that SHA-3 is slow; it links to https://www.imperialviolet.org/2016/05/16/agility.html , which doesn't seem related, and matches the previous link. I wonder if that was supposed to link to somewhere else, like http://bench.cr.yp.to/results-sha3.html (as linked from https://www.imperialviolet.org/2012/10/21/nist.html )?
From that, SHA-3 certainly doesn't run significantly faster than alternatives (variants of BLAKE do indeed outperform it), but it seems roughly on par with SHA-256/SHA-512. But "on par" doesn't give any incentive to switch.
I wonder how much relative attention the SHA-3 winner (Keccak) gets compared to other alternatives, like BLAKE?